MySql进阶

MySql进阶
MR.XSSMySql进阶
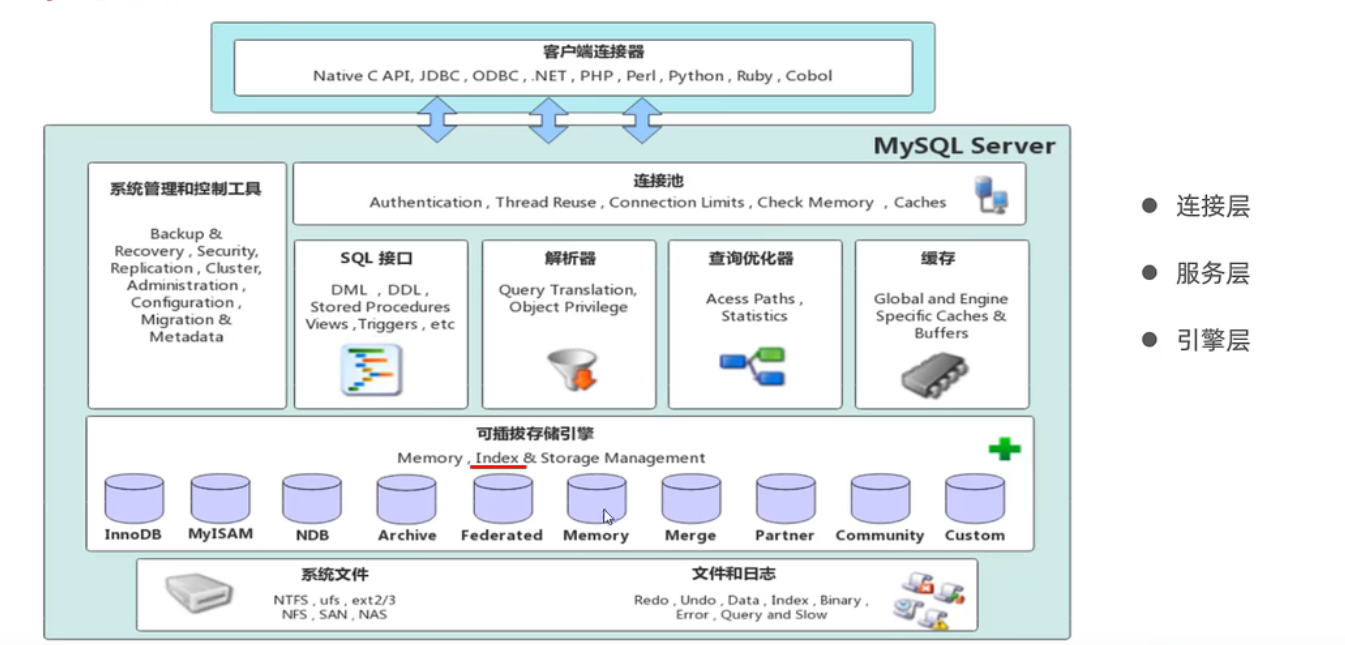
存储引擎
MySql体系结构
InnoDB是Mysql5.5以后默认的存储引擎
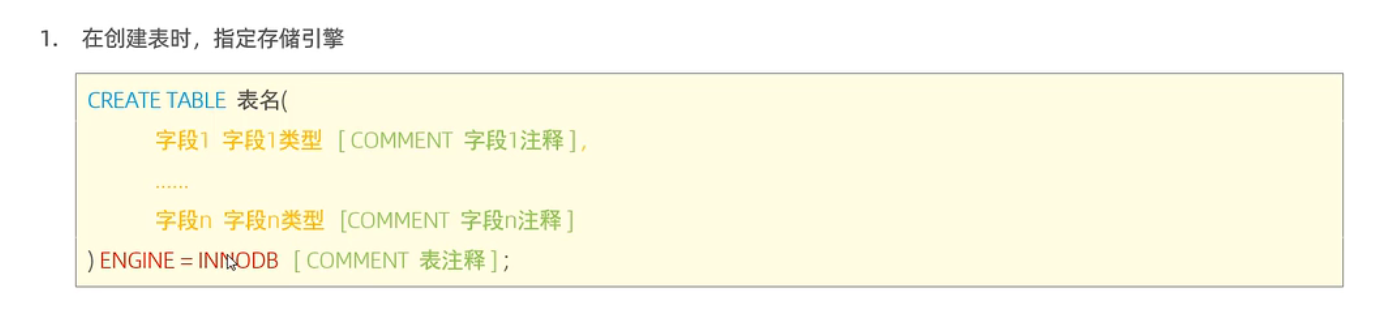
创建表的时候可以指定存储引擎
查询当前数据库支持的引擎
show engines;
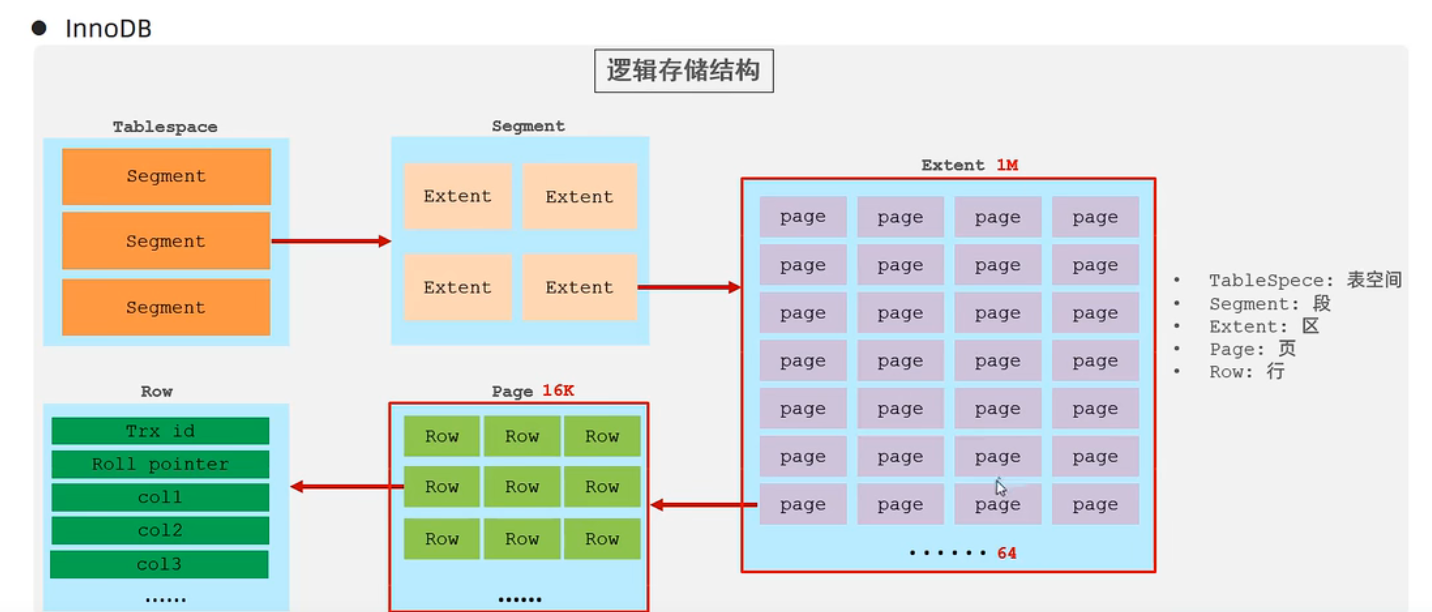
InnoDB存储引擎
简介

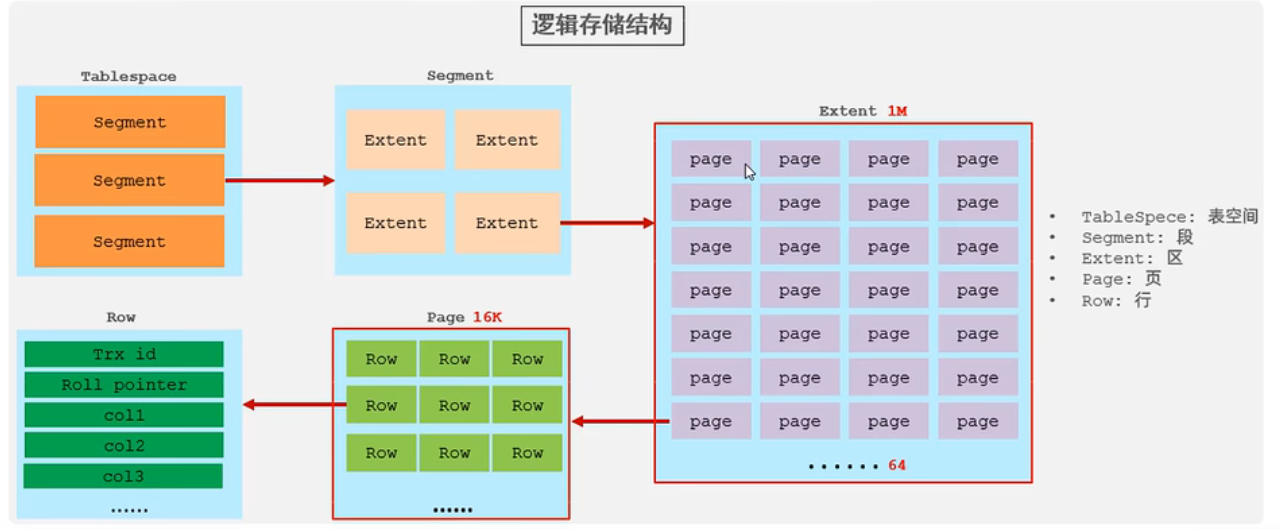
逻辑结构
MyISAM存储引擎

Memory存储引擎

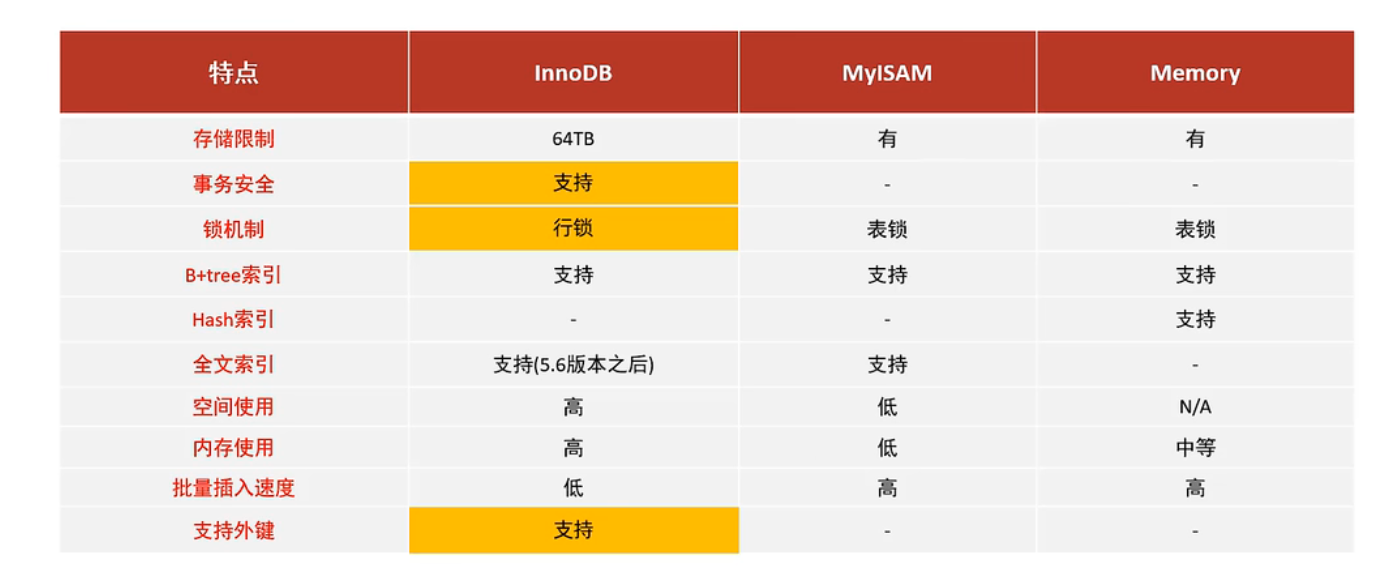
存储引擎的特点

索引
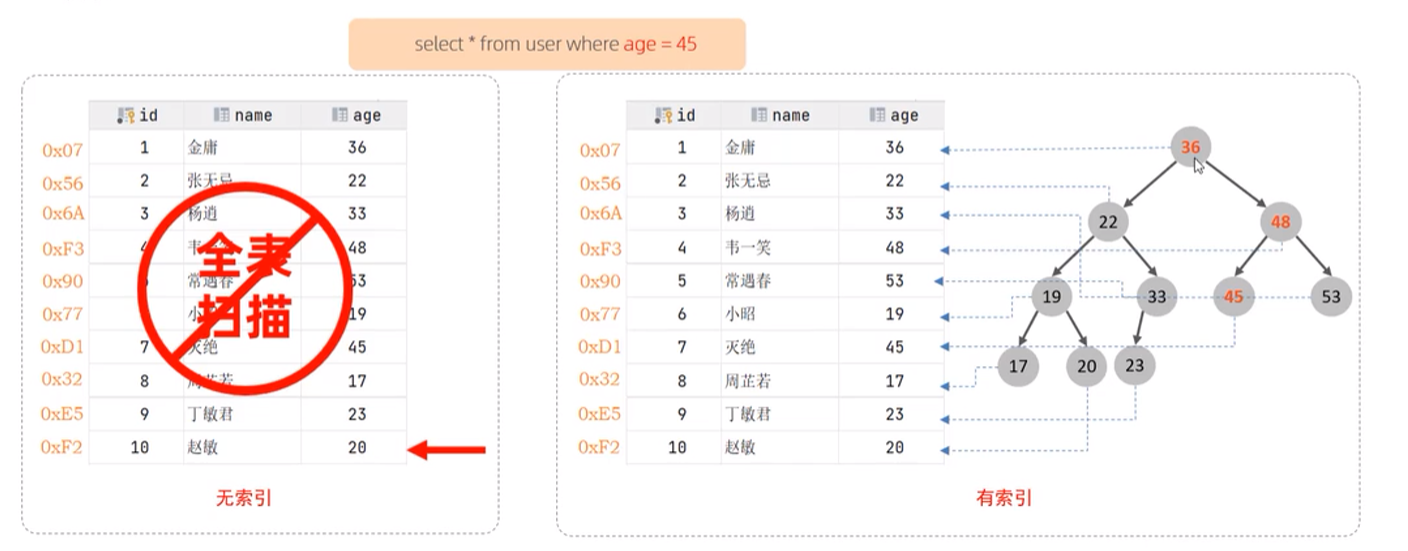
索引概述
介绍

演示
优缺点


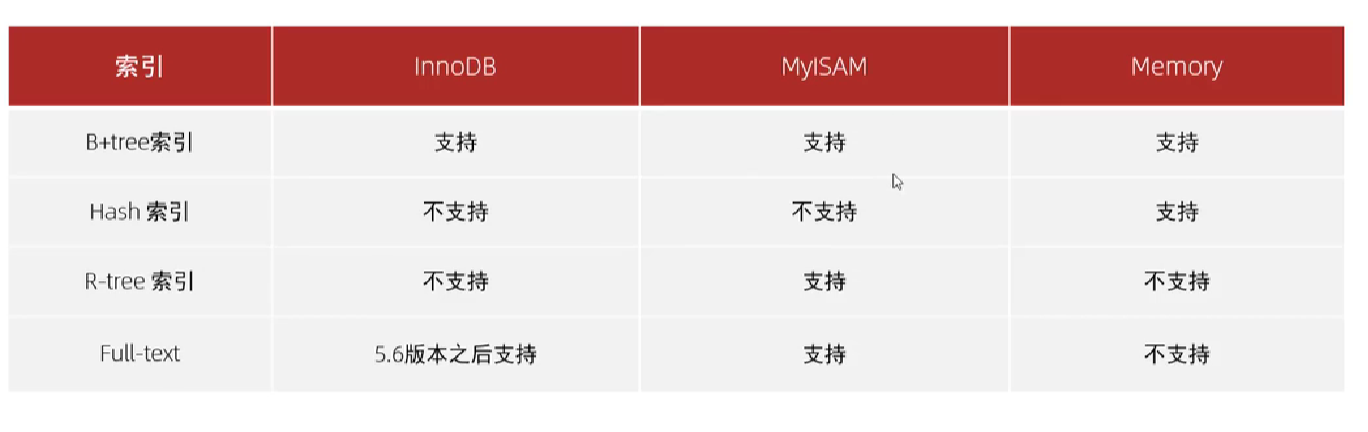
索引结构
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的结构,主要包括一下几种:

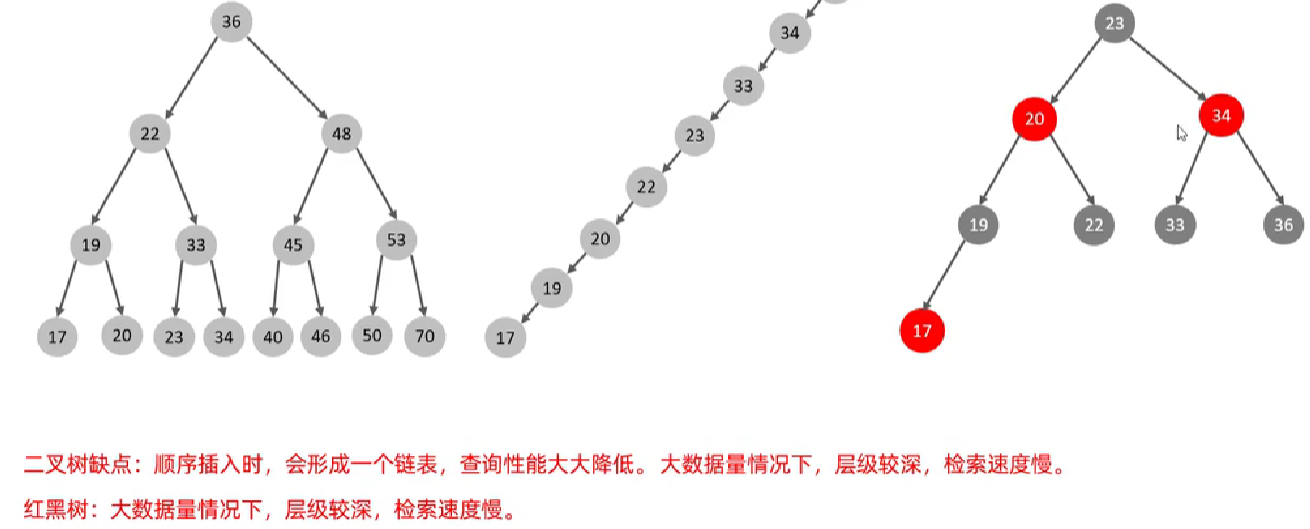
二叉树
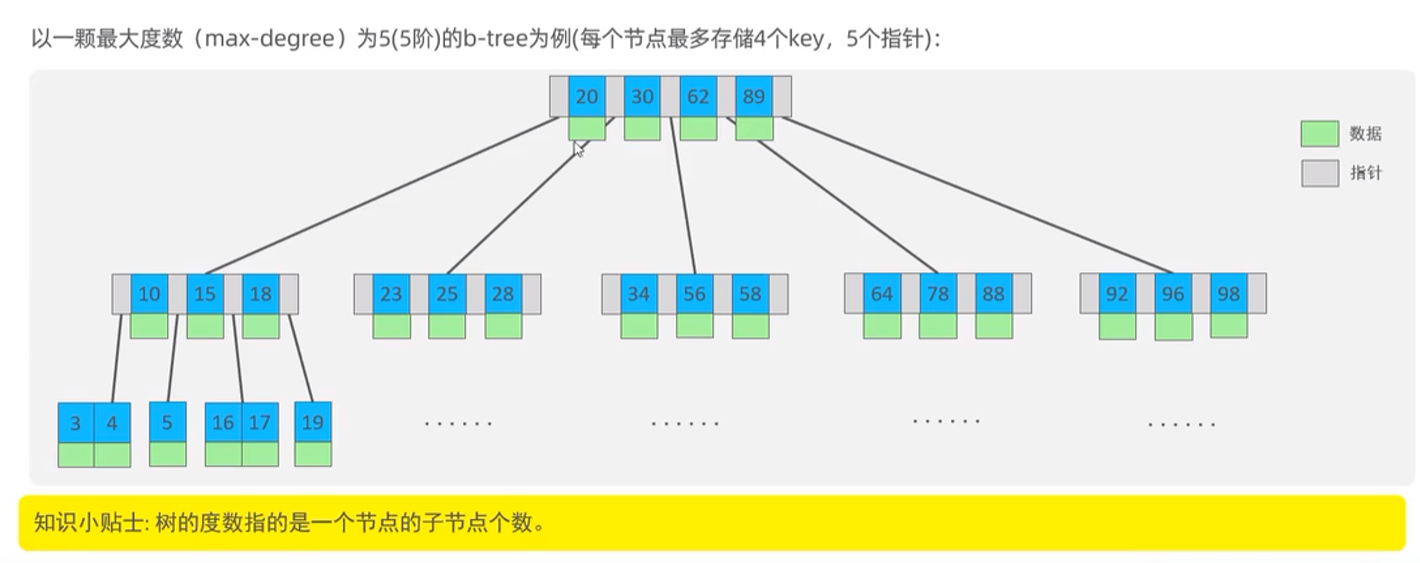
B-Tree (多路平衡查找树)
当存储的key等于阶数,此时会发生向上裂变
B+ Tree
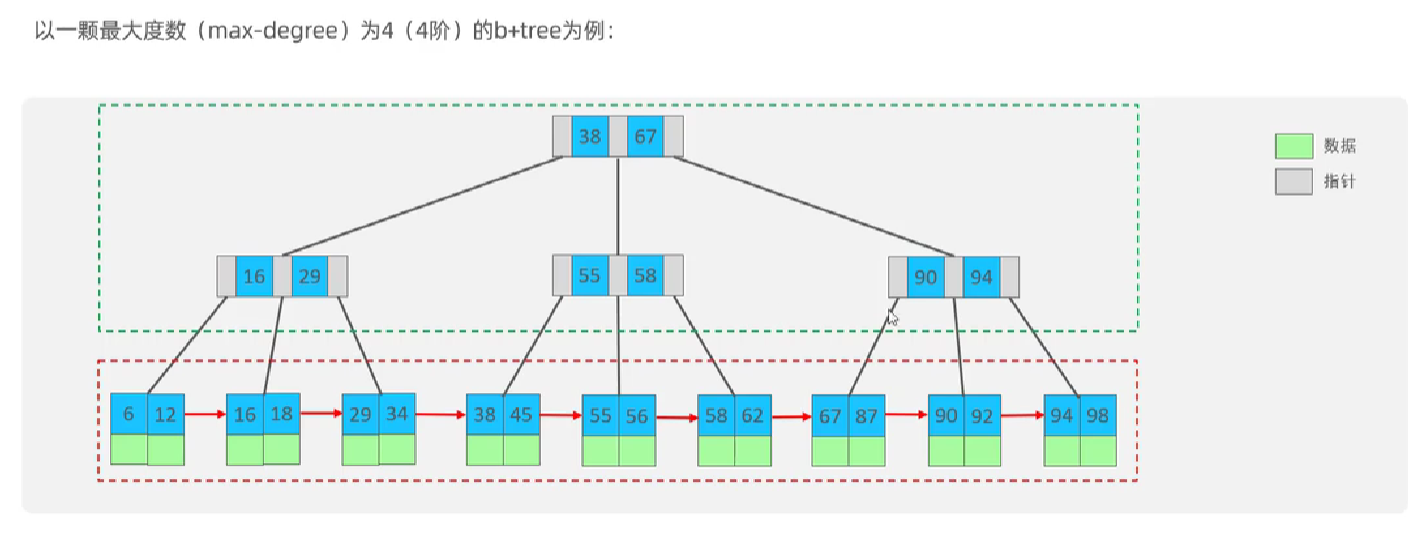
b+树数据存储在叶子节点,并且叶子节点是链表
当存储的key等于阶数,此时会发生向上裂变,叶子节点但是向上裂变的同时还会存在于叶子节点,并且会生成一个单向链表
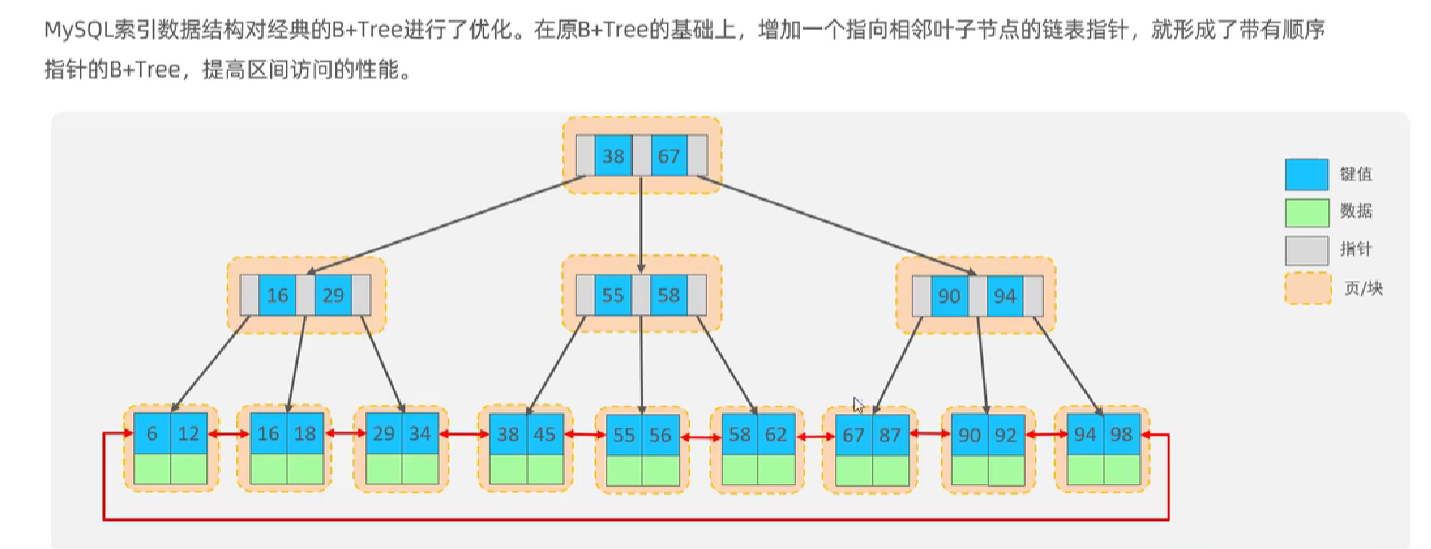
MySQL 对 B+ 树进行了优化
Hash索引
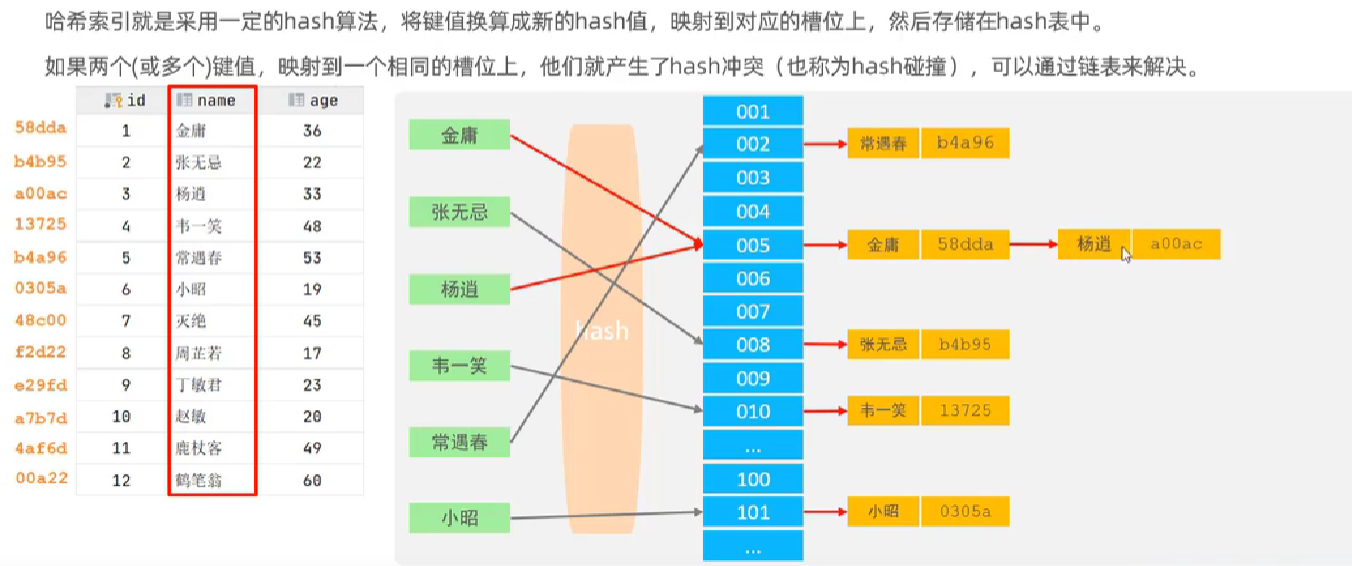
哈希索引特点

当出现哈希冲突,就不是一次检索
存储引擎支持

为什么采用B+树索引

相对于hash索引,B+树支持范围匹配以及排序操作
索引分类
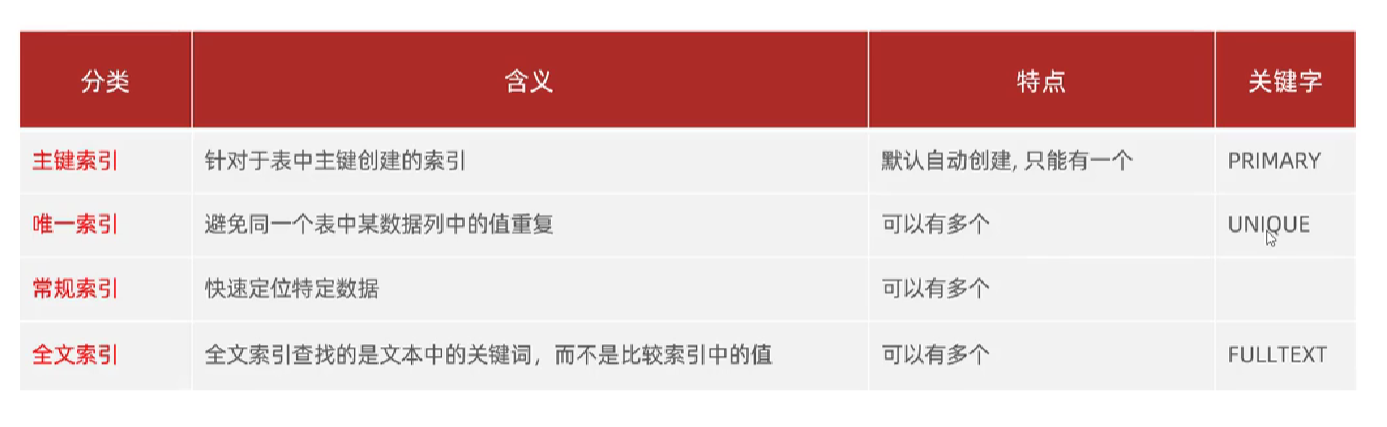
在InnoDB 存储引擎中,根据索引的存储形式,可以分为以下两种

聚集索引选取规则

示例
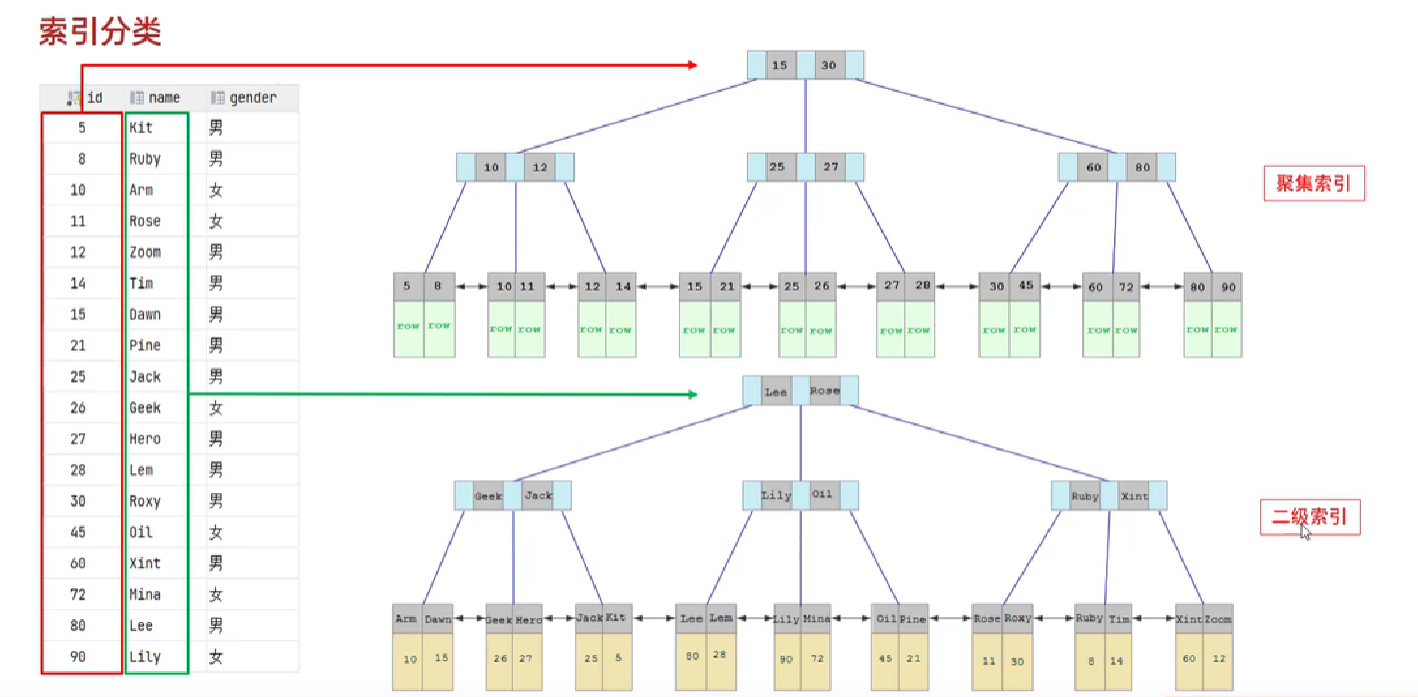
注:
聚集索引叶子节点下面挂载的是本行的数据,而二级索引叶子节点挂载的本行的id值
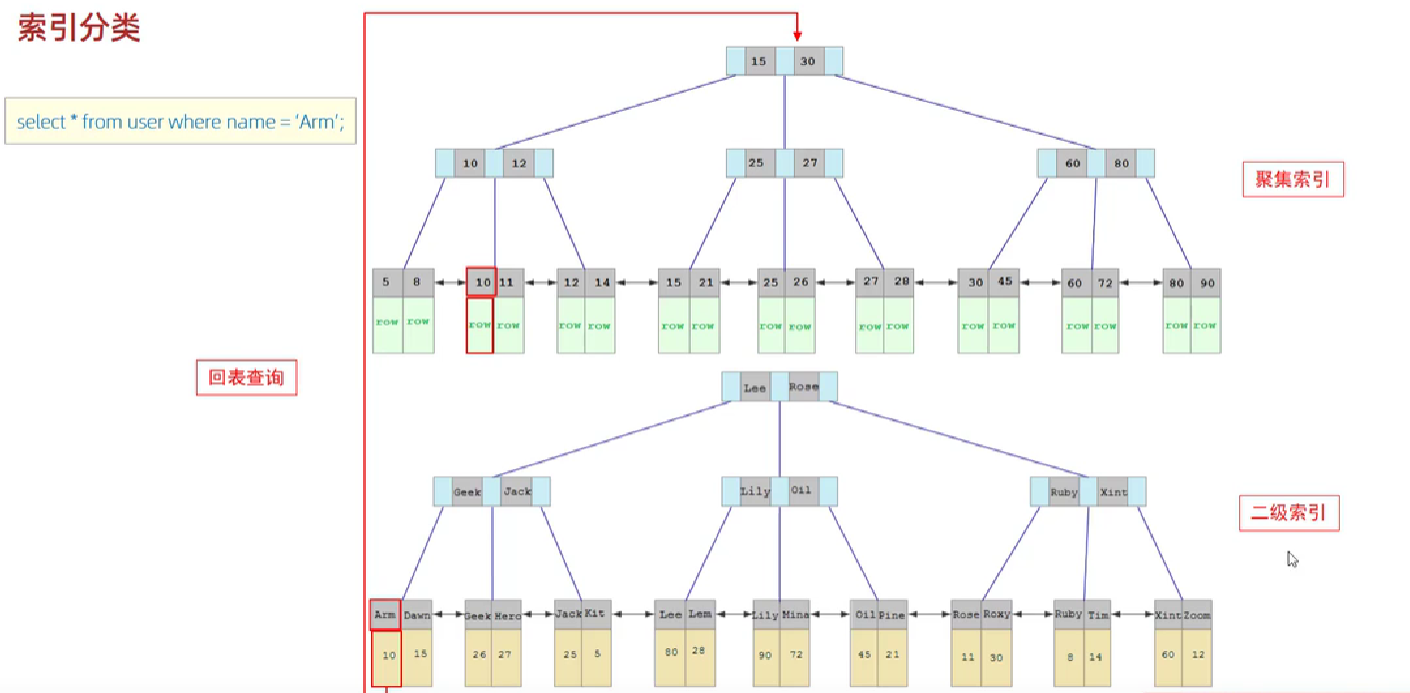
回表查询
执行下面的sql语句,已知name字段建立了二级索引,此时条件为name等值查询,先走二级索引拿到id值,又因为查询的为所有字段,此时走聚集索引,根据id拿到本行的数据。
索引操作语法
创建索引
查看索引
删除索引



SQL性能分析
主要对查询语句进行优化
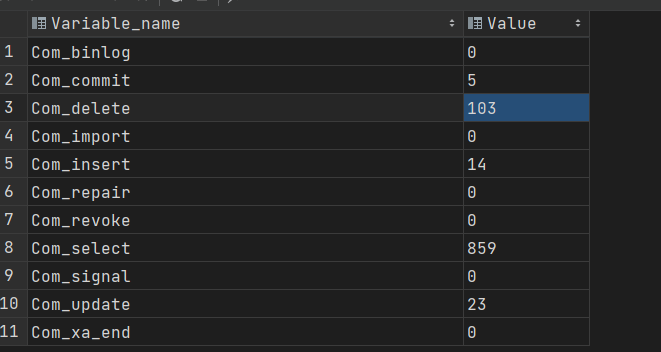
SQL执行频率

1 | show global status like 'Com_______';//7个下划线 |
慢查询日志
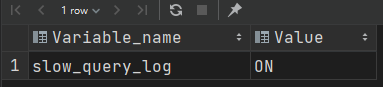
查看慢查询日志是否开启
1 | show variables like 'slow_query_log'; |

1 | systemctl reastart mysqld; //重启mysql服务 |
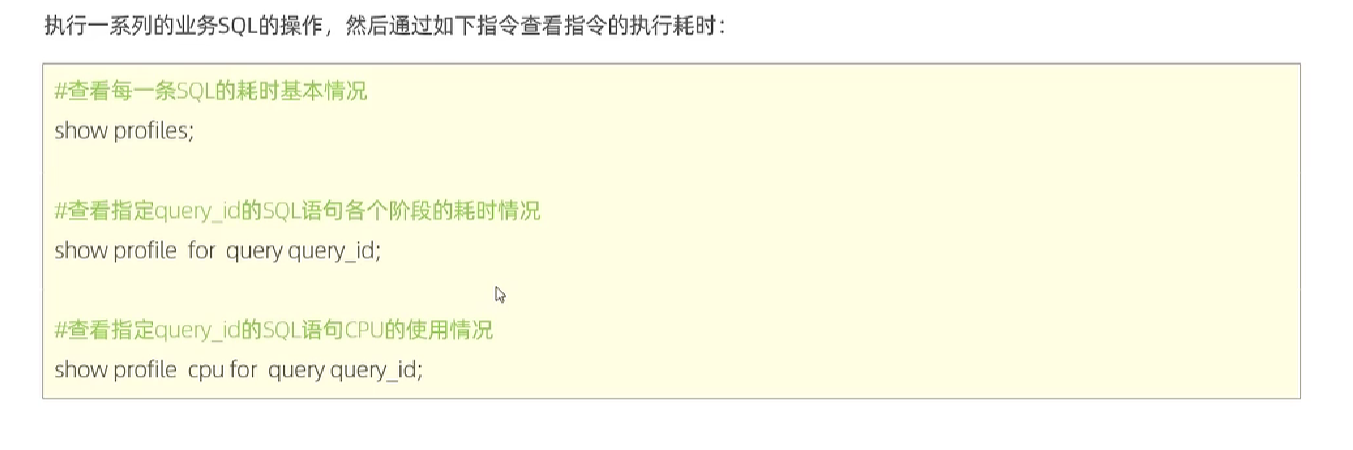
profile详情
数据库的 profiling 可以帮助我们分析数据库的性能瓶颈,了解每个 SQL 语句执行的消耗时间、I/O 操作、CPU 开销等细节。通过 profiling,可以发现程序设计和数据库调优中的问题,从而提升数据库的性能
可以查看sql语句耗时情况
1 | show profiles; |

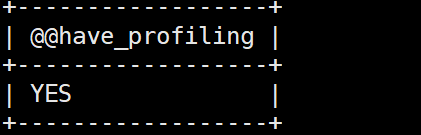
是否支持profiling
1 | select @@have_profiling; |
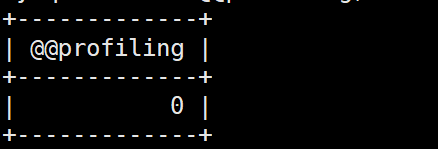
是否开启profiling
1 | select @@profiling; //0是关闭,1是开启 |
explain执行计划


explain执行计划各字段含义
id
select_type
type(重要,越靠前性能越好)
possible_key(***)
key(***)
key_len(***)
rows(***)
filtered
Extra
在前面的字段中没有显示的值会在这里显示








索引使用
验证索引效率
在未建立索引之前,执行sql语句,查看sql耗时
针对字段创建索引
1 | create index 索引名称 on 表名(字段名); |
注:在数据量较大时候,创建索引也比较耗时,创建索引成功之后,查询速度提升十分迅速
最左前缀法则
注意:只要存在创建索引时最左边的哪个索引就会走索引,与查询时索引所在的位置不同,否则就不会走

profession,age 和 status建立了联合索引
注:最后两条sql跳过最左侧字段,导致索引失效,将不会走索引进行查询
范围查询
注意:这里右侧索引失效指的是创建索引时的右侧索引会失效,自己并不会失效

注:在业务允许的情况下,尽量使用 >= 可以解决范围查询索引失效问题
索引失效情况一
- 不要在索引列上进行运算操作,该索引后面的索引将会失效

字符串不加单引号,索引将失效
模糊匹配


总结
范围不带等号,左边界模糊匹配,在索引字段上使用操作符,字符串不加引号会发生隐式转换,不遵守最左前缀树法则,在这几种情况下,索引会发生
索引失效情况二
or连接的条件
用or分割的条件,只有两侧有索引的情况下,才会对索引进行触发
数据分布影响
数据分布占数据库表的大部分时,数据库会走全表扫描的情况


SQL提示
SQL提示,是数据库优化的一个重要手段,简单地说,就是在SQL语句中加入一些人为提示达到优化的目的
use只是建议,MySQL不一定接受

覆盖索引(解决回表)



前缀索引
解决大字段类型,在索引使用时浪费大量的磁盘io的问题

语法
1 | create index 索引名称 on 表名(column(n)); //n表示字符串前缀 |
前缀长度

1 | select count(distinct 字段)/count(*); //选择性,值越高,效率就越高 |
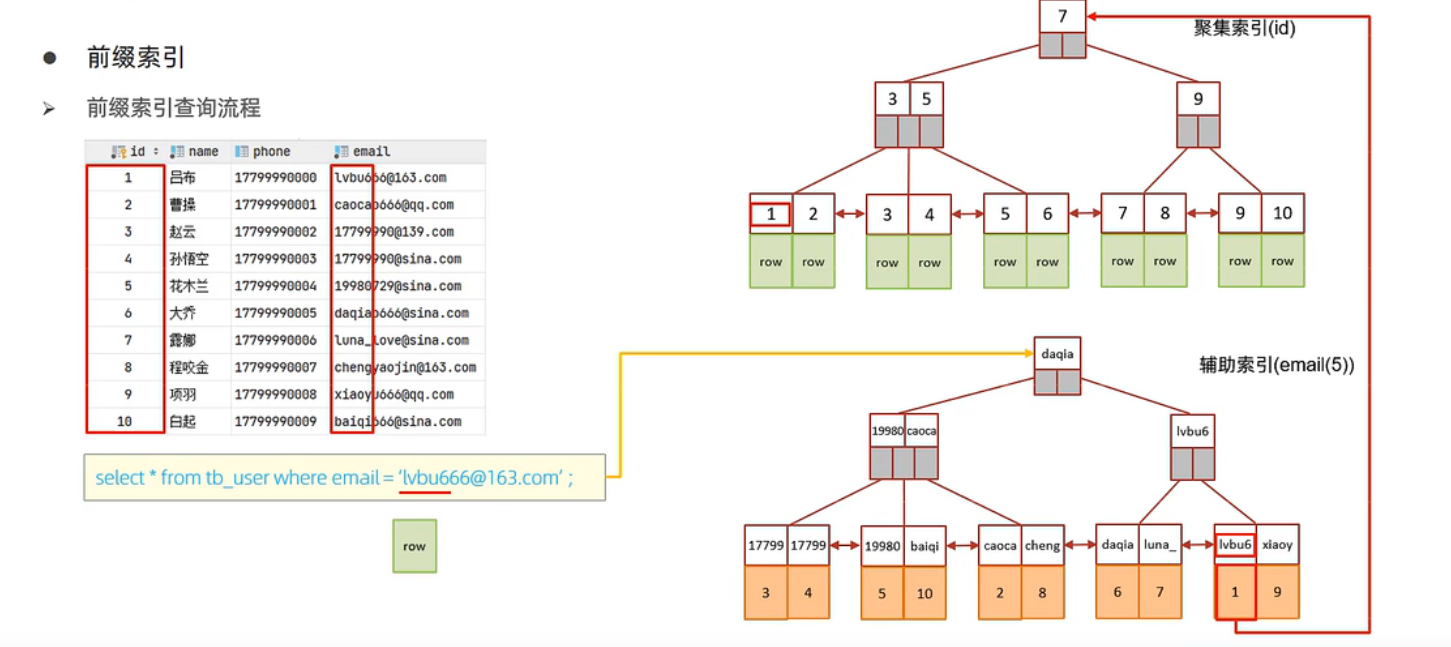
单列索引和联合索引使用规则
联合索引能有效的规避回表查询,提高查询速度,对sql进行了优化


1 | select id,name,phone from user where name='吕布' and phone='17799990000'; |
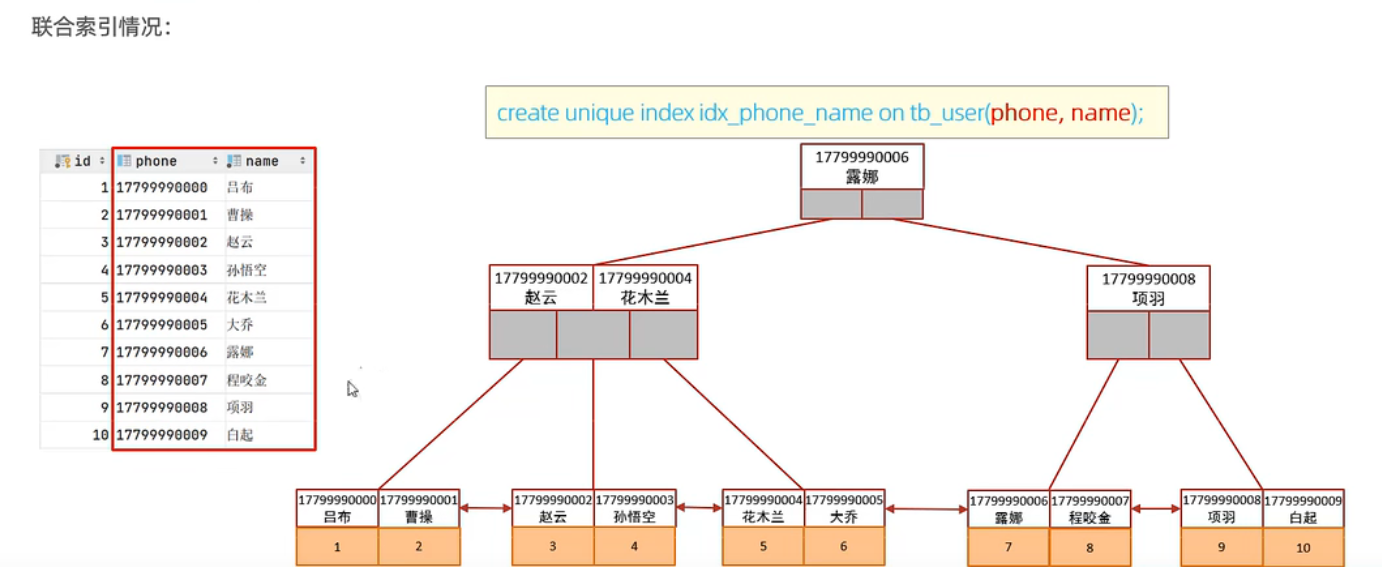
上述sql语句执行时不需要回表查询,原因是该联合索引叶子节点挂载的是主键id,返回查询数据时,直接将索引和id一起返回,不需要回表
索引使用原则

小结

注:
在InnoDB存储引擎中必须有聚集索引,聚集索引一般为主键,没有主键,mysql会指派一个,聚集索引叶子节点挂载的是一行的数据

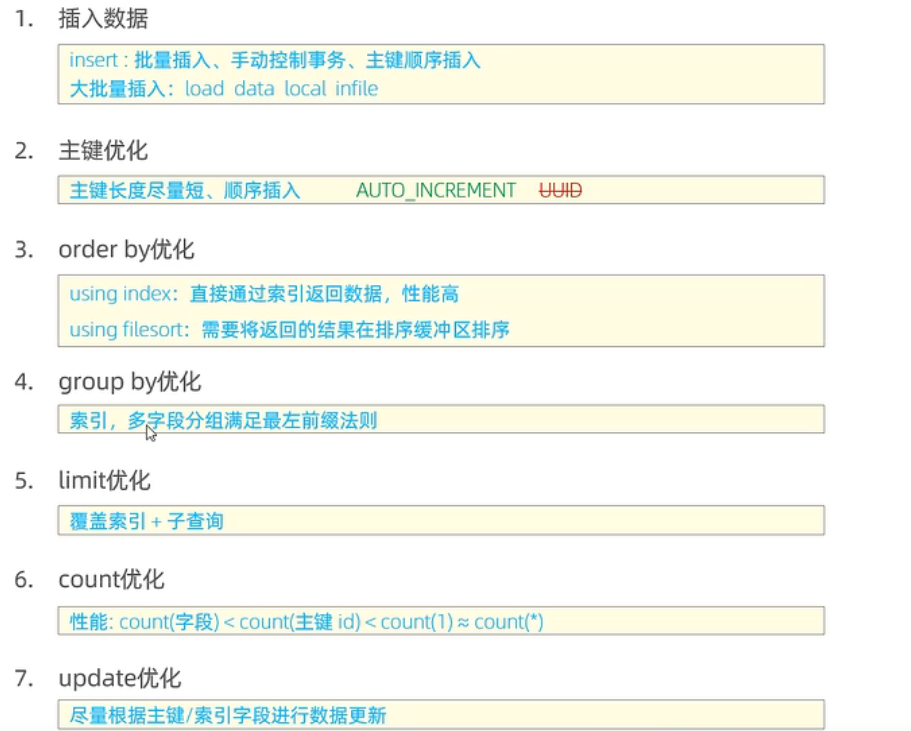
SQL优化
插入优化
insert 优化
批量插入(500-1000条比较合适),避免数据库网络连接浪费时间
手动提交事务—避免事务的重复开启与关闭
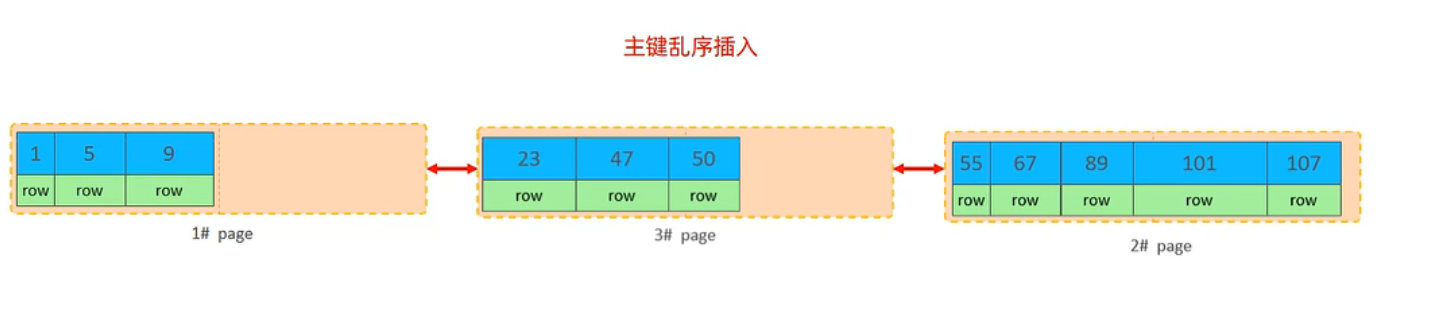
主键顺序插入
大批量插入数据

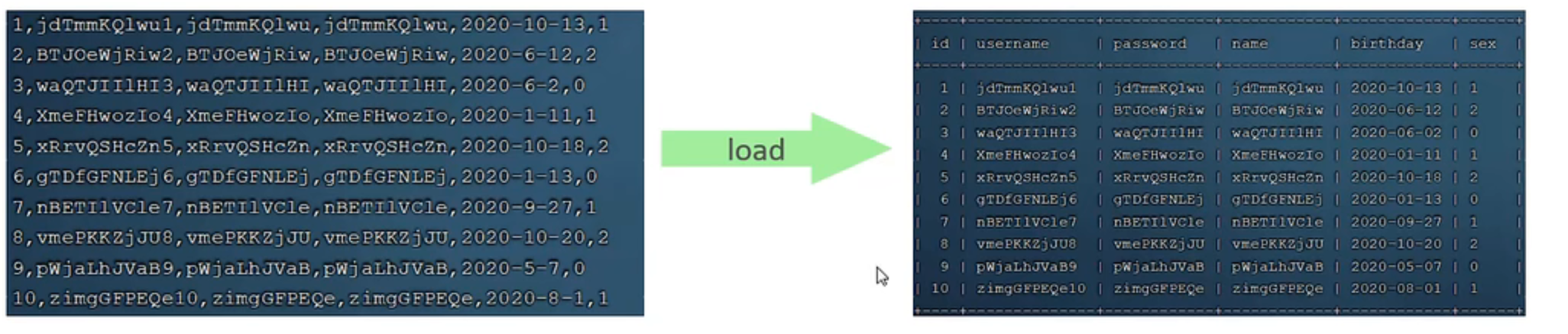
1 | mysql --local-infile -uroot -p //参数--local-infile在登录数据库的时候加上 |
主键优化
数据的组织方式
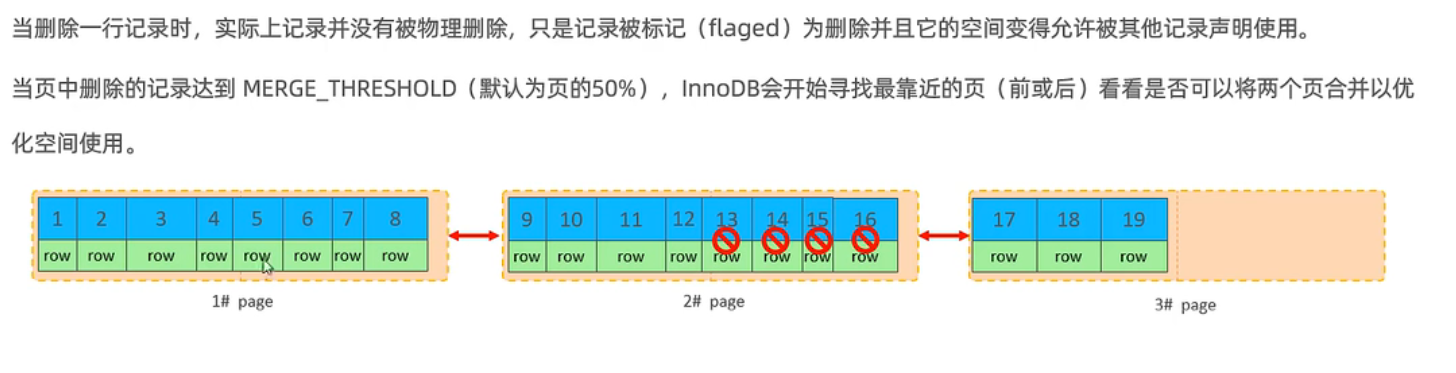
页分裂
页合并
主键设计原则
- 满足业务需求的情况下,尽量降低主键的长度
- 插入数据时,尽量选择顺序插入,选择AUTO_INCREMENT自增主键
- 尽量不使用UUID做主键或者其他自然主键,如身份证号
- 业务操作时,尽量避免对主键的修改



order by优化

使用覆盖索引



1 | //大数据量排序时,可以适当增大缓冲区大小 |
group by优化
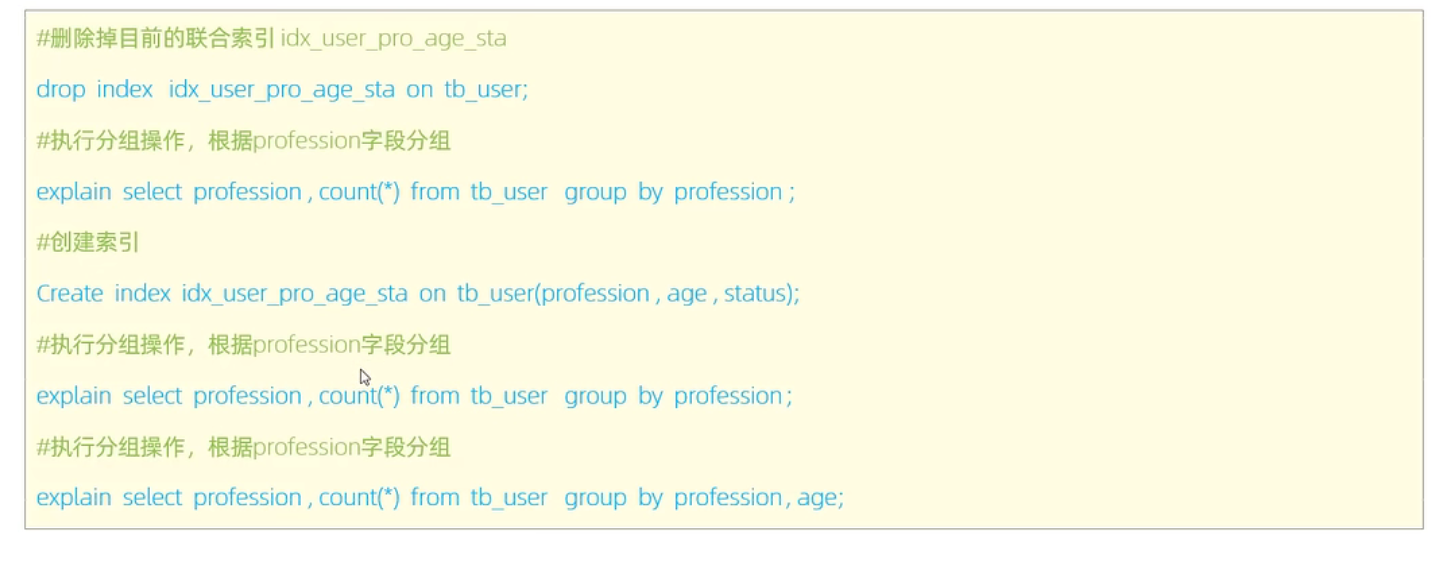
当删除掉所有索引之后(使用临时表)

创建索引之后(联合索引(age,profession)),只要符合最左前缀法则就会走索引

分组条件只有age

limit优化
limit分页,当数据量比较大时,数据量越大,性能会越来越低
例如
1 | select * from emp limit 5000000000,10; |
此条查询记录就是仅仅返回10条数据,其他数据丢失,查询条件巨大
优化思路,一般分页查询时,创建覆盖索引可以较好的提升性能,可以通过覆盖索引加上子查询方式进行优化
count优化

优化思路:
自己计数
count用法





update优化

更新数据的时候尽量走索引,防止事务之间发生阻塞
总结
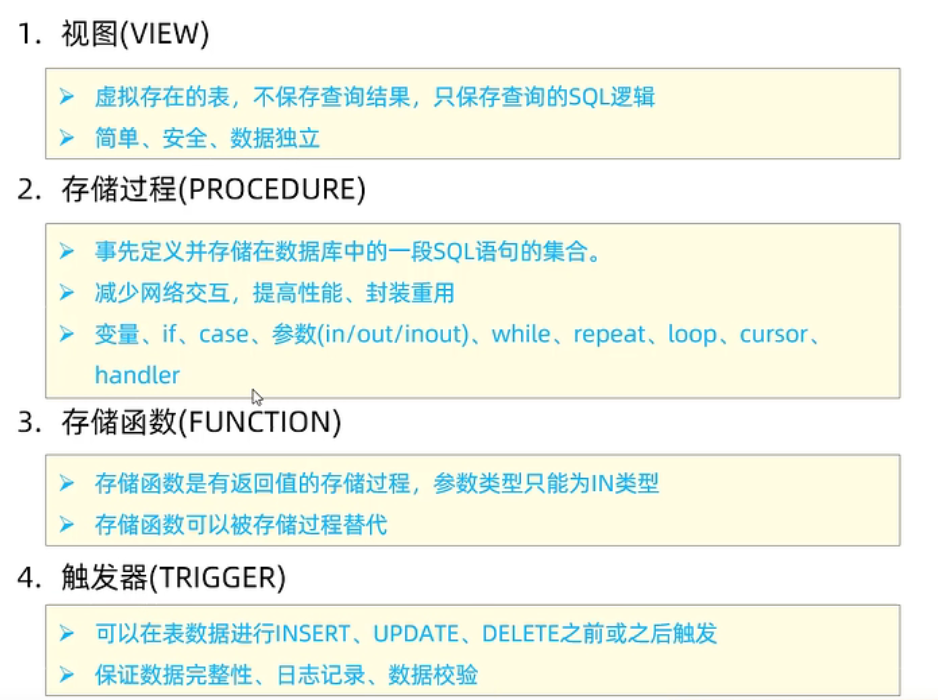
视图,存储过程,触发器
视图

创建视图
查询
修改
删除




视图检查选项

cascaded :检查依赖视图条件
local:有酒检查,没有就不检查
存储过程
介绍
特点
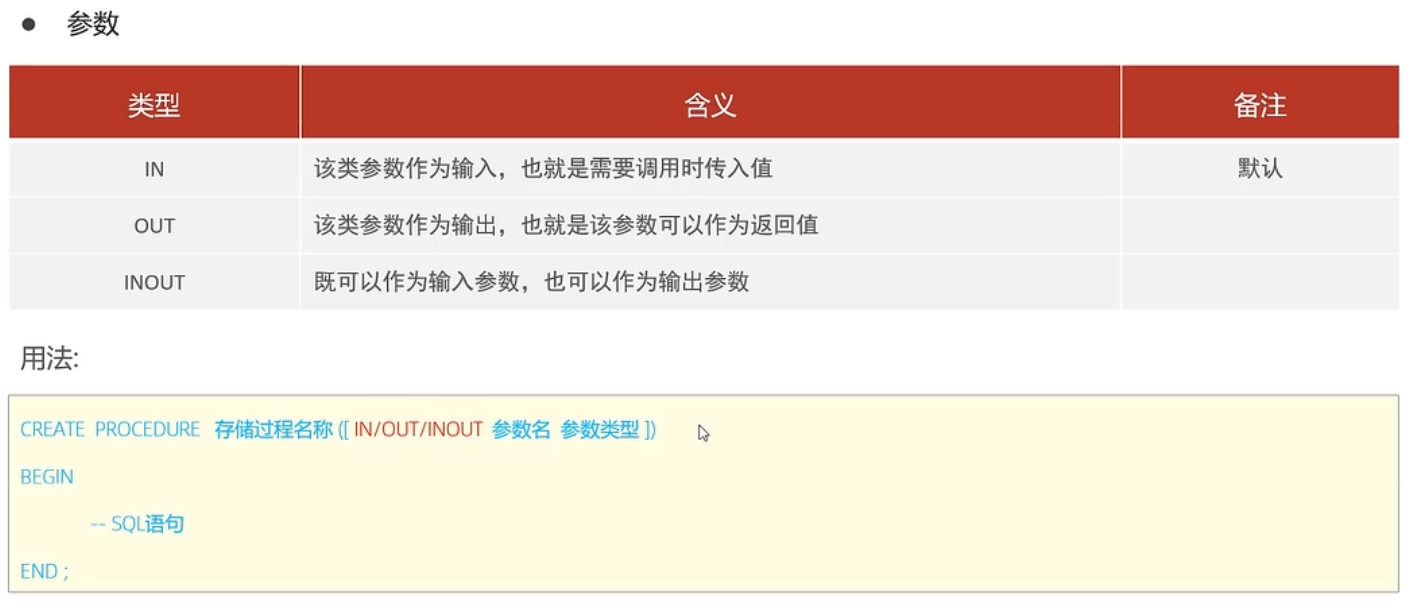
创建
1
2
3
4create procedure p1()
begin
select count(*) from sys_role_menu;
end;调用
查看存储过程
1
2//查看oa表中的存储过程
select *from information_schema.ROUTINES where ROUTINE_SCHEMA='oa';1
2//查看存储过程语句
show create procedure p1;
1
2//删除存储过程p1
drop procedure if exist p1;






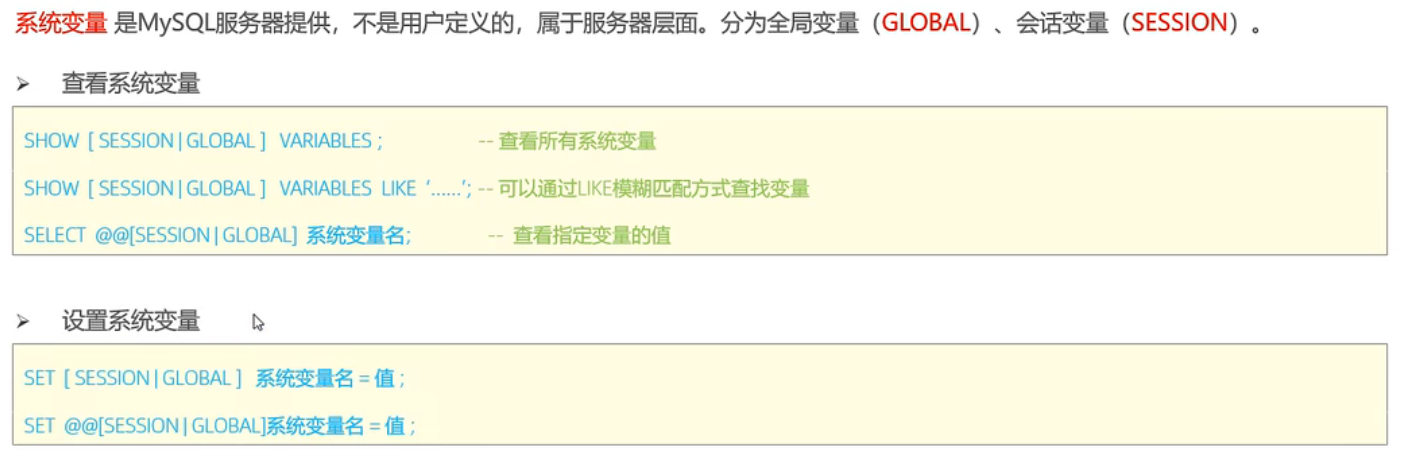
变量
- 系统变量
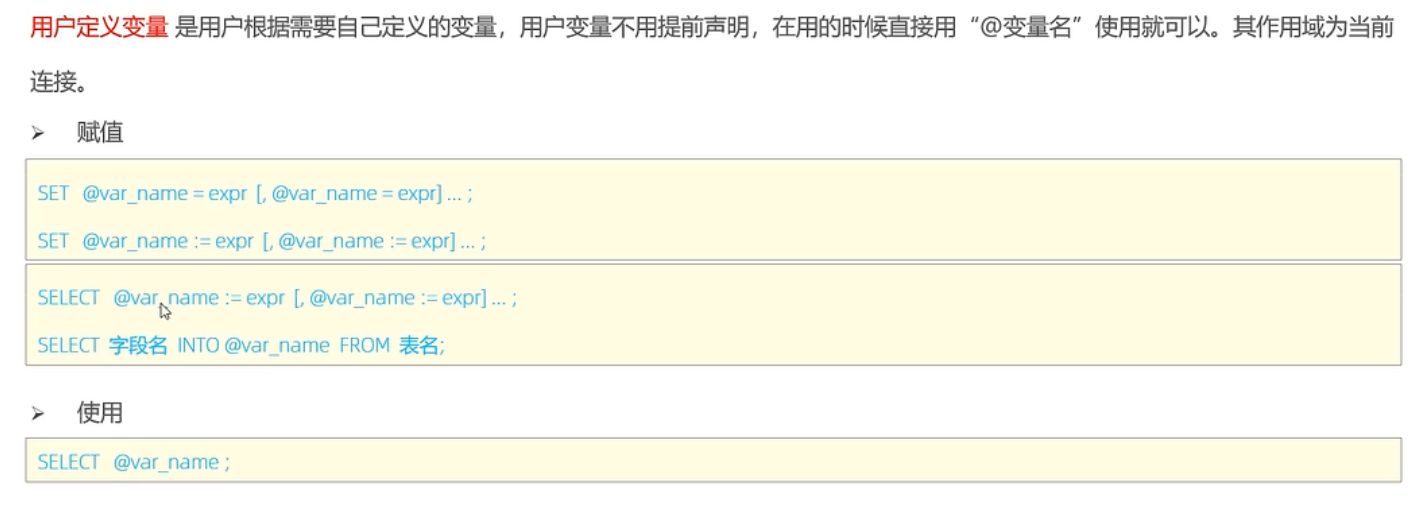
用户变量
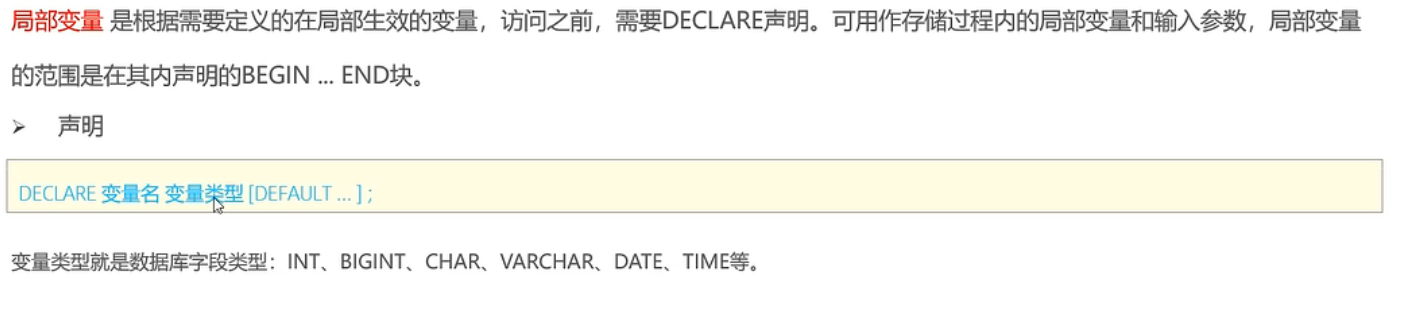
局部变量
1
2
3
4
5
6
7create procedure p2()
begin
//声明局部变量
declare stu_count int default 0;
//为变量赋值
select count(*) into stu_count from student;
end;

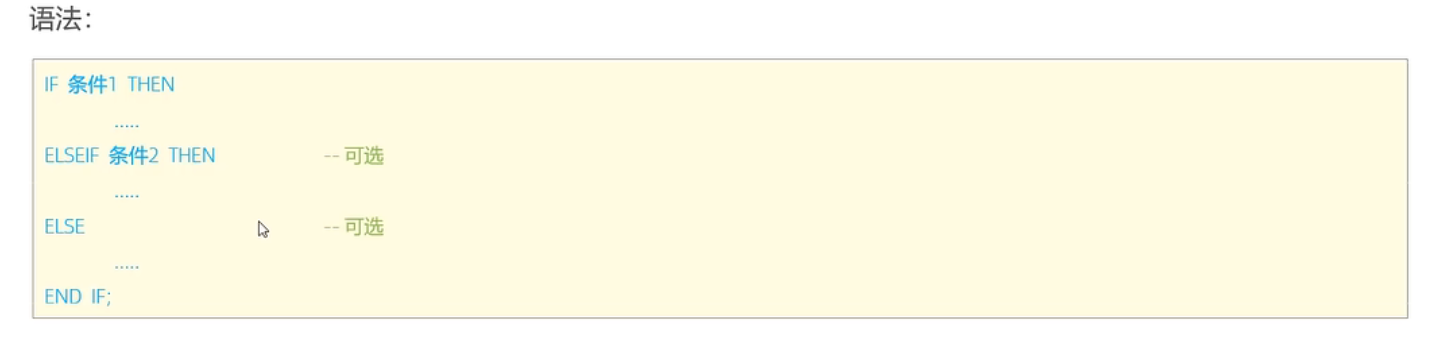
if
参数
inout类型在输入之前先对变量进行赋值
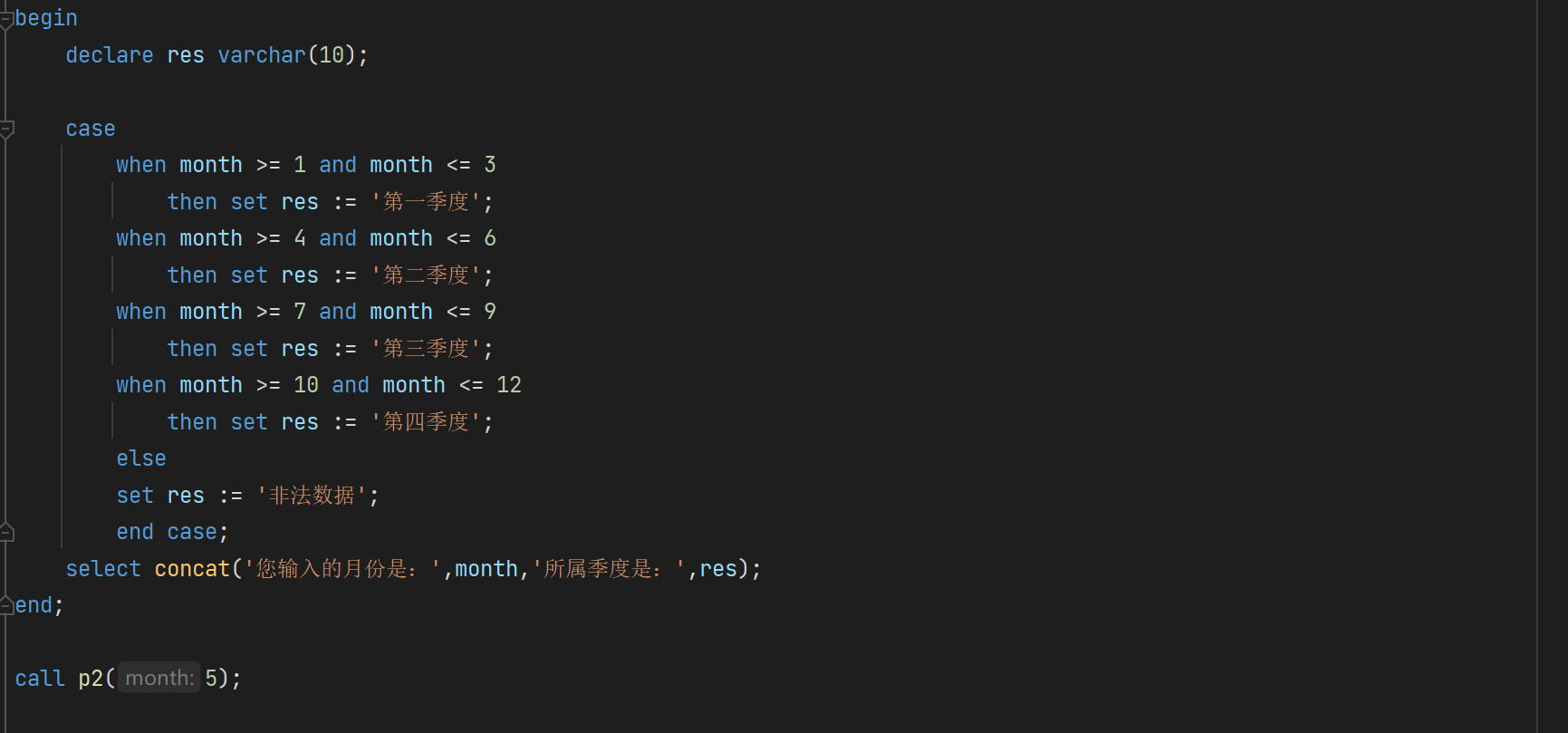
case
语法一
语法二



while

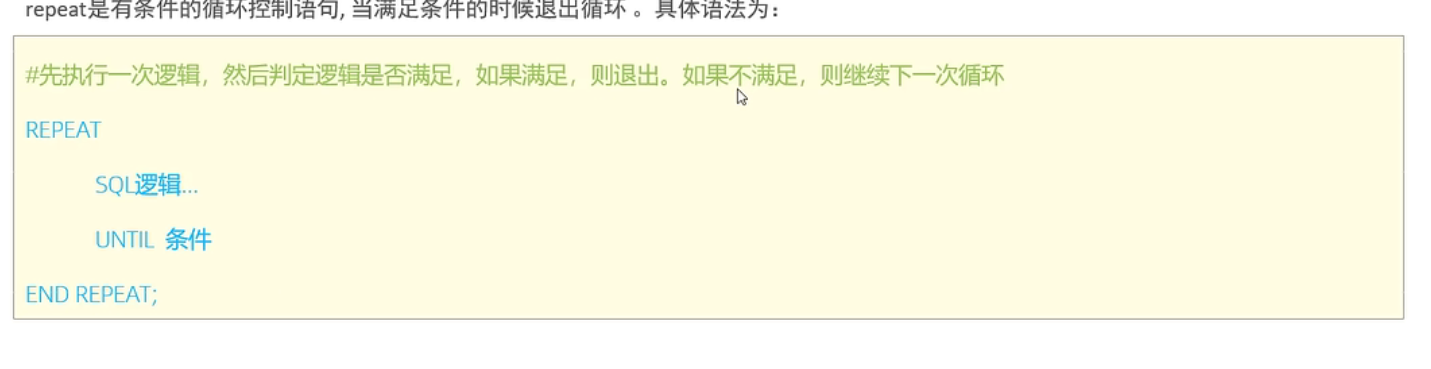
repeat
loop


游标


条件处理程序
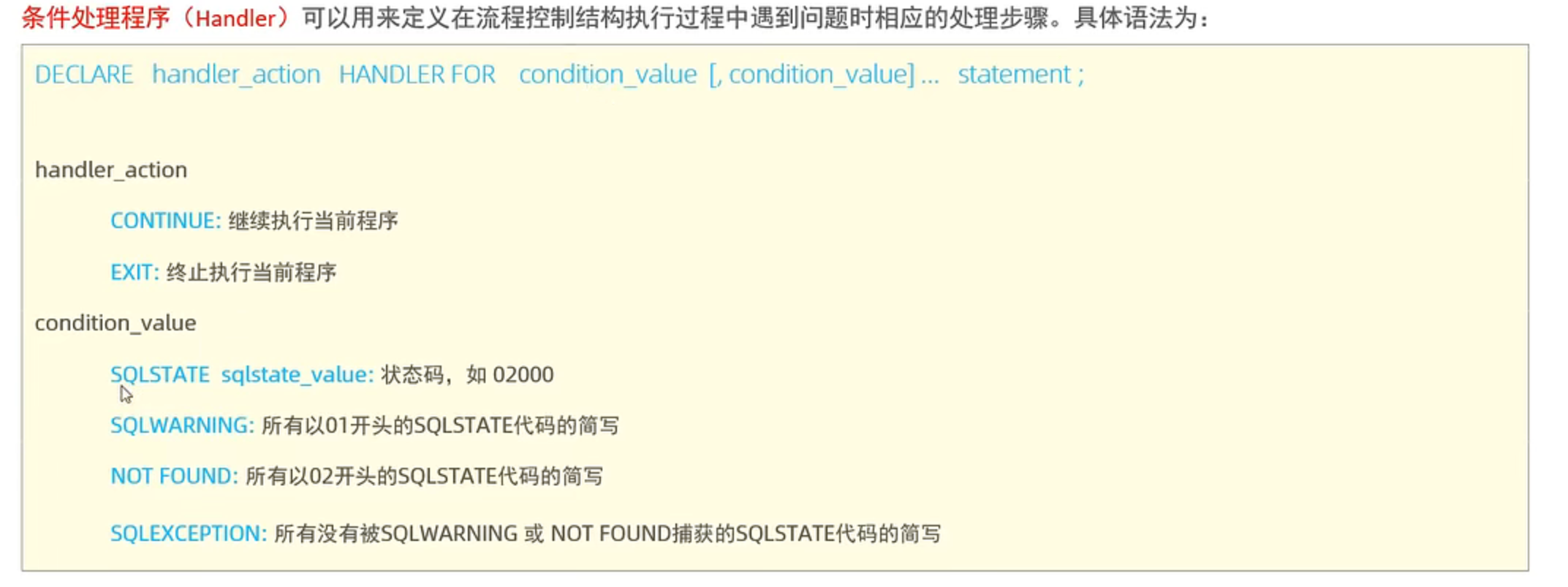
1 | create procedure p1(in uage int) |
存储函数

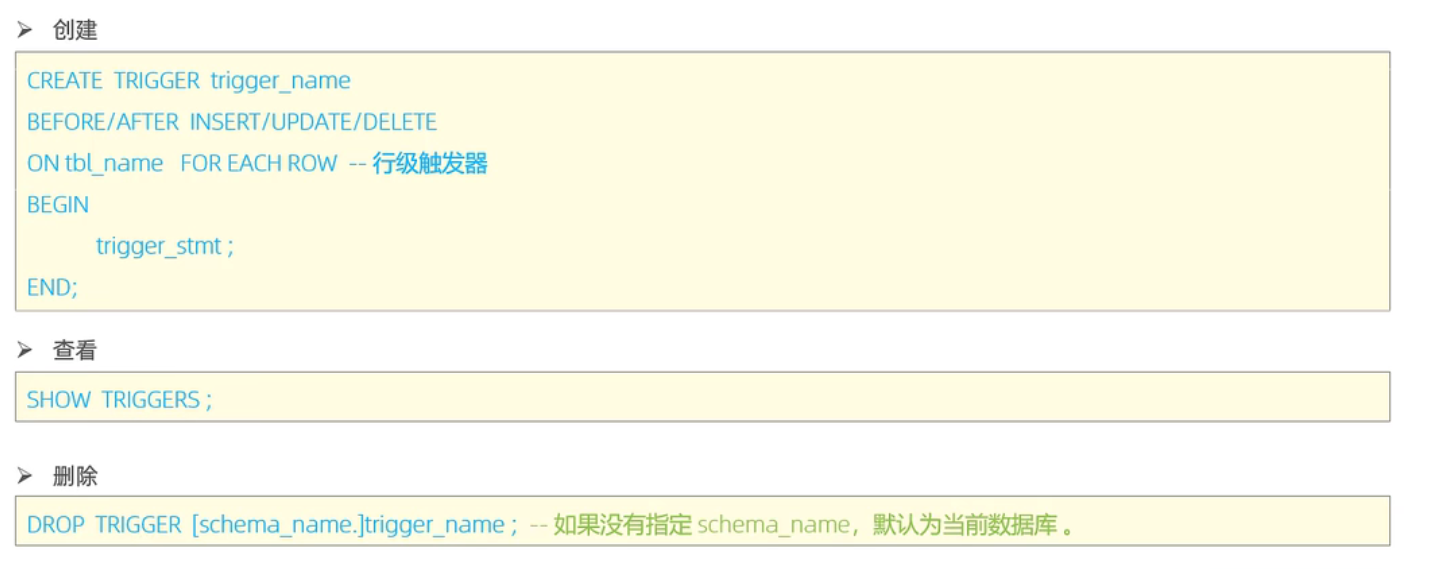
触发器
介绍


语法
new.id是新数据的id new指代新数据
old.id 是旧数据id old指代旧数据
小结
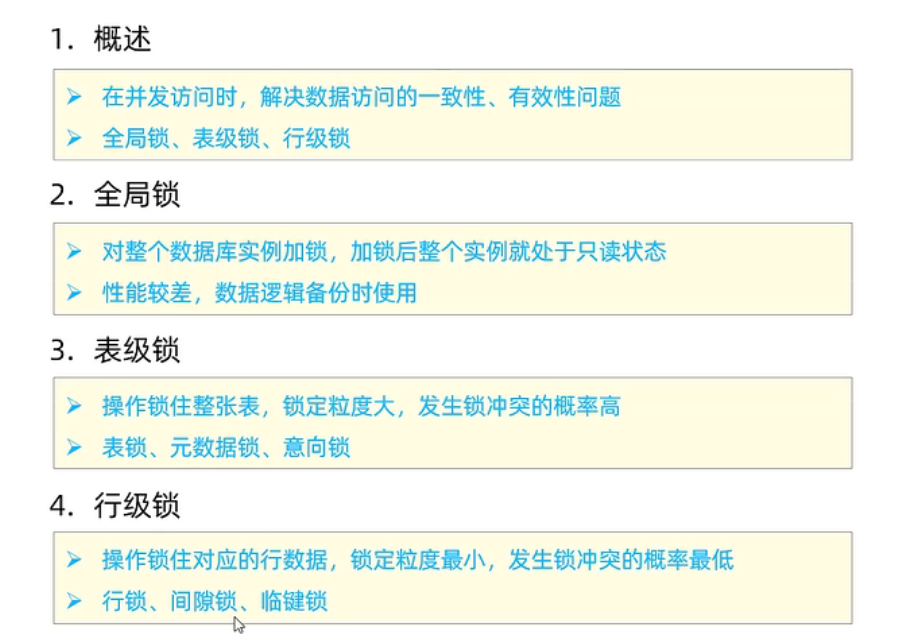
锁
介绍
分类


全局锁

未加锁,可读可写,数据不一致
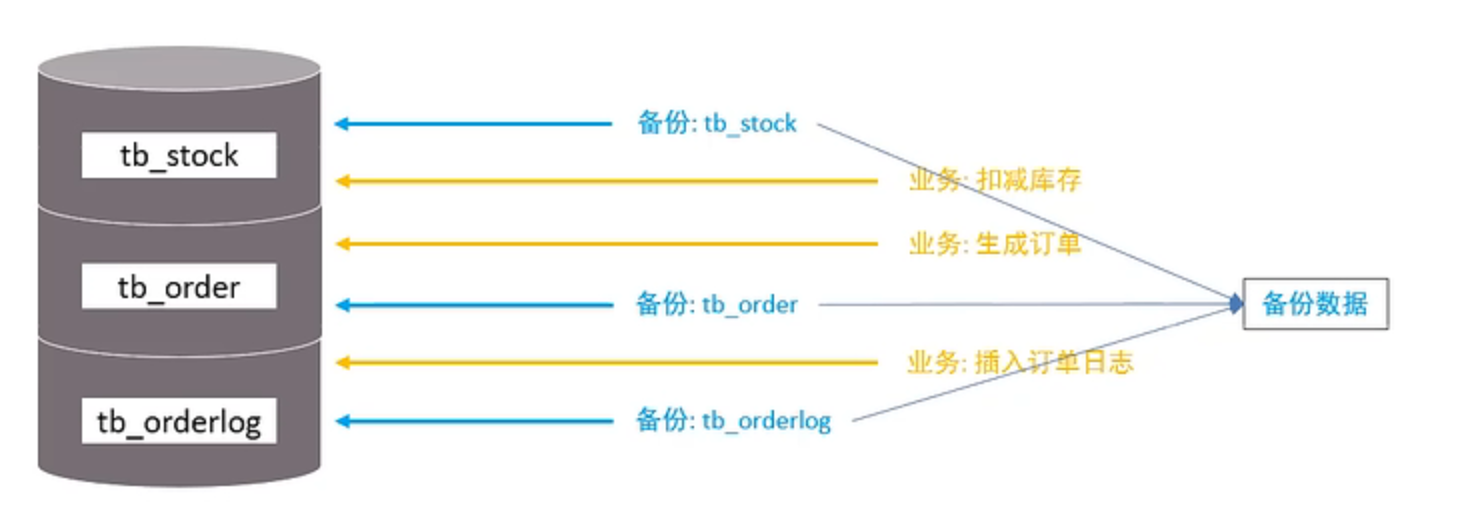
加上全局锁之后,只可读,不可写
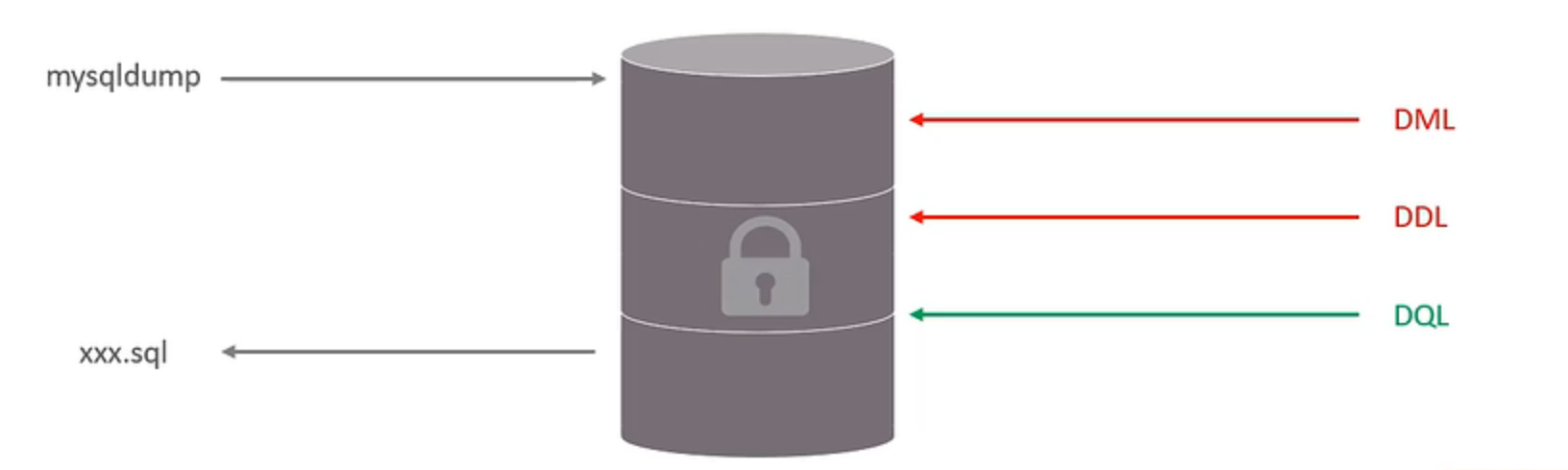
1 | #加上全局锁 |
- 特点

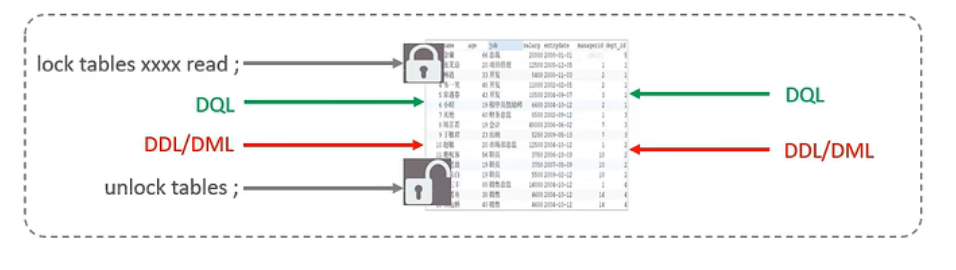
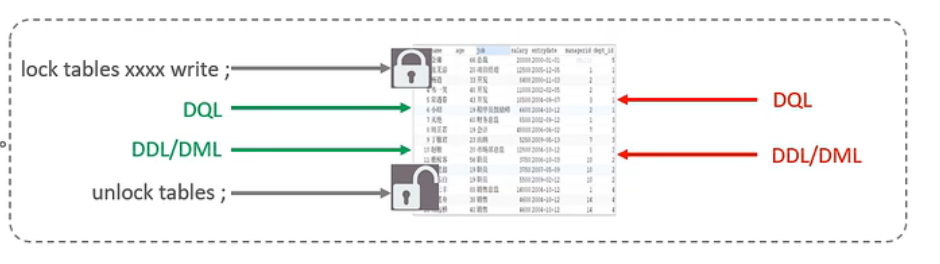
表锁
对于表级锁,主要分为三类

- 表锁

1 | #加锁 |
读锁不影响其他连接读,影响其他连接写,当前连接也不能写
写锁,其他连接不能读也不能写

元数据锁
意向锁
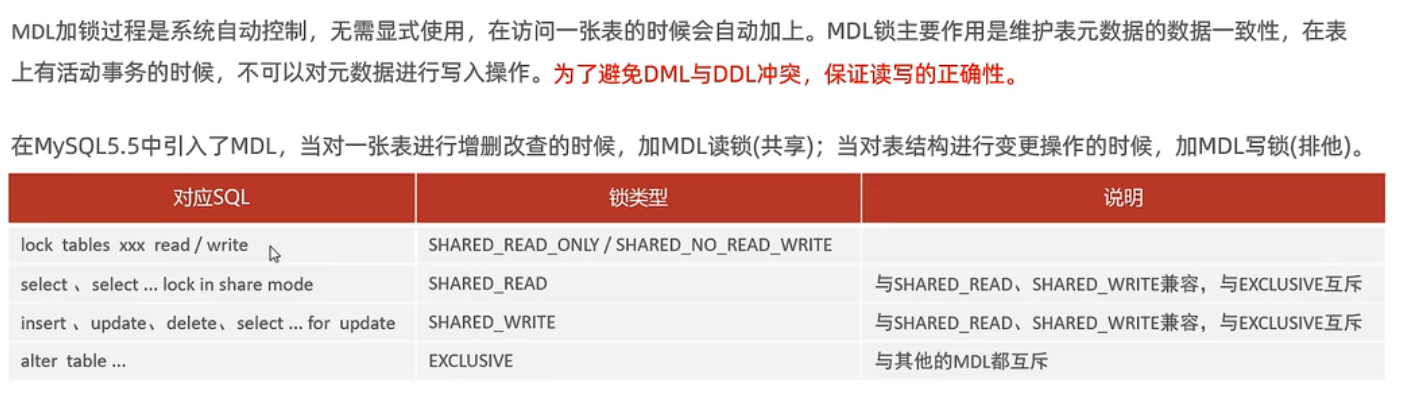

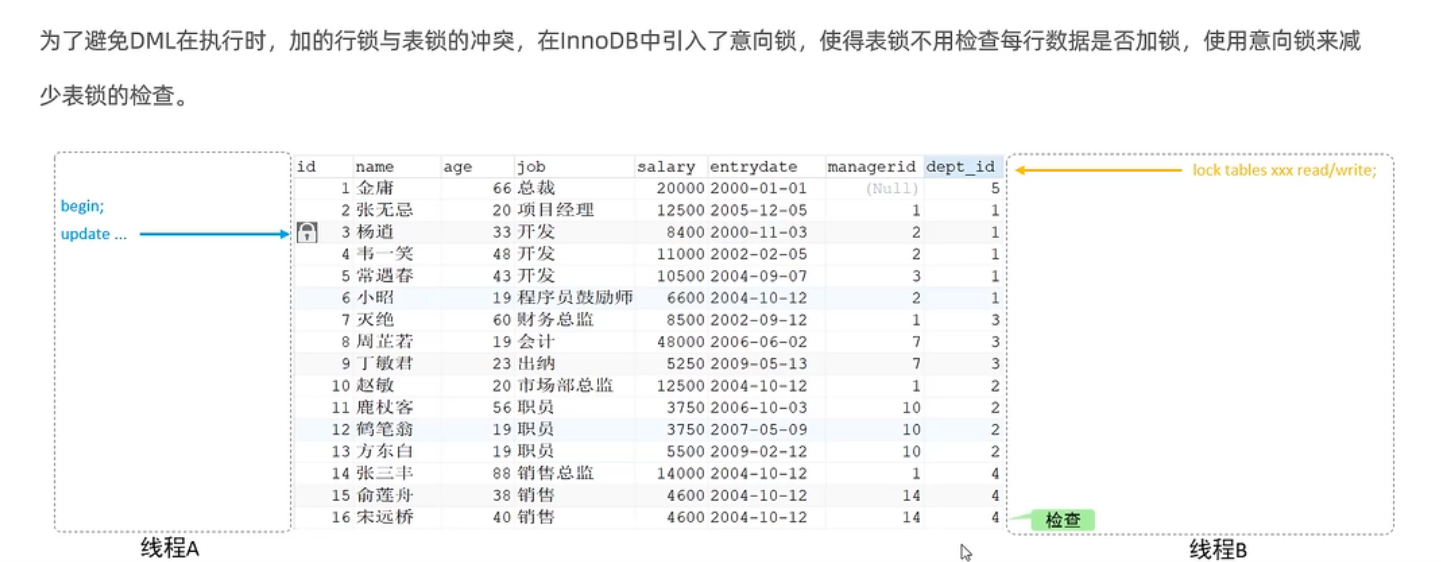

行锁
介绍
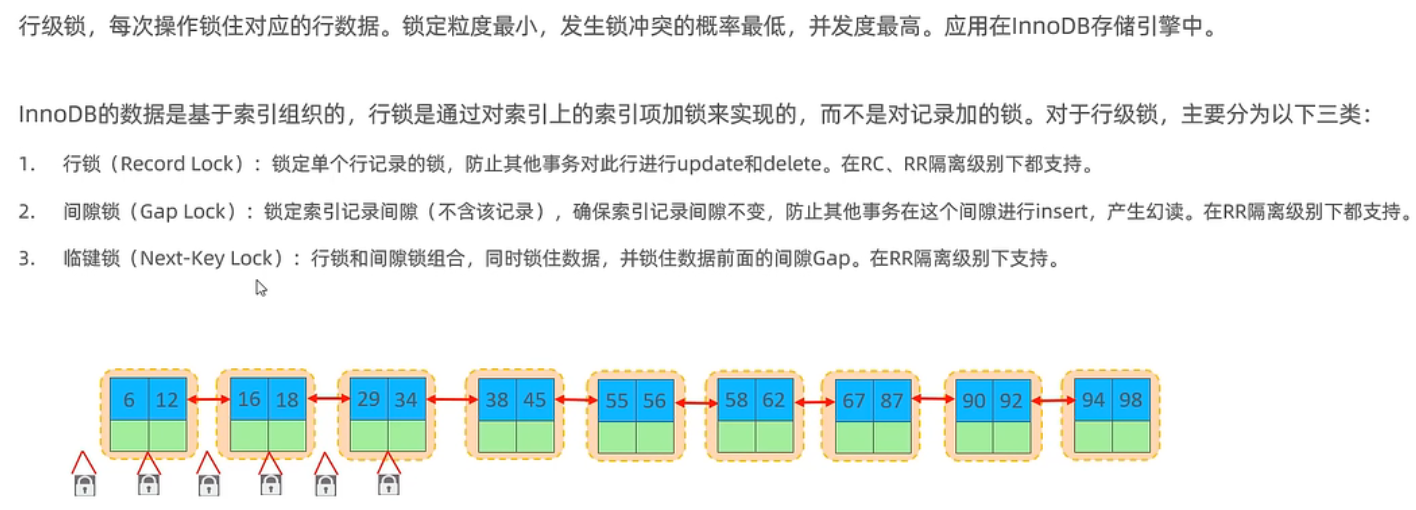
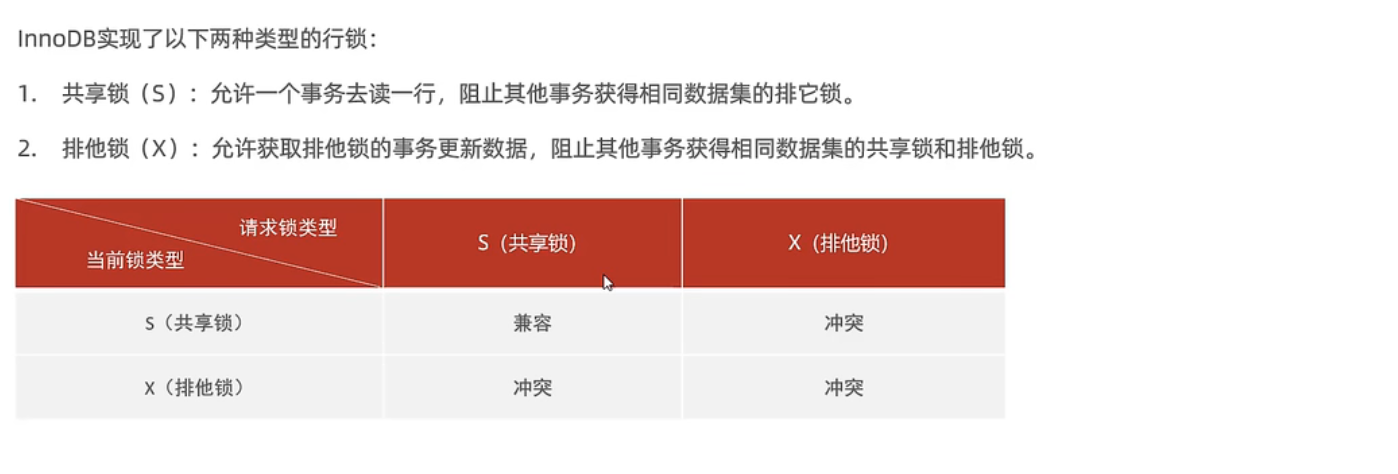
行锁
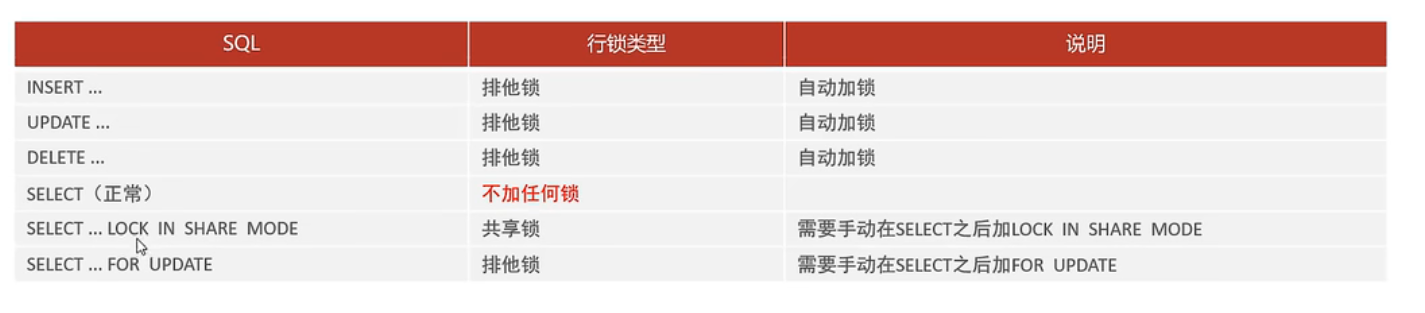


间隙锁(GAP)

小结